
BERT OVERVIEW
BERT: Bidirectional Encoder Representations from Transformers
1. Input Representation(입력 표현)
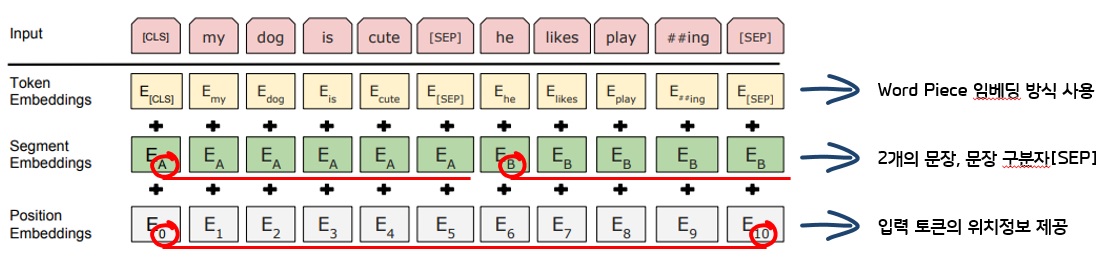
| 1. Token Embeddings | 1) 일반적인 워드임베딩 방식을 사용하지 않음 |
| 2) word piece 임베딩 방식을 사용 | |
| 3) oov(out of vocabulary)처리에 효과적, 정확도 상승 (bcoz of 2)) | |
| 2. Segment Embeddings | 1) 두개의 문장을 문장구분자 [SEP]와 함께 합쳐 넣는다 |
| 2) 입력길이 제한, 두 문장은 합쳐서 512 subword이하로 제한 | |
| 3. Position Embeddings | 1) 입력 Token의 위치 정보 제공 |
2. Pre-Training BERT(언어모델링 구조)
| 1단계: 입력문장들을 임베딩하여 언어를 모델링하는 언어모델링 구조 과정 |
| 2단계: 이를 fine-tuning하여 자연어처리 task를 수행하는 과정 |
| 1. MLM: Masked Language Model |
| 2. NSP: Next Sentence Prediction |
2.1. 언어모델링 데이터
BERT는 총 3.3억(8억 단어의 BookCorpus + 25억 단어의 Wikipedia 데이터)의 거대한 말뭉치를 이용하여 학습
거대한 말뭉치를 MLM, NSP 모델 적용을 위해 스스로 라벨을 만들고 수행하므로 준지도학습이라고 한다.
| 1. BERT-base(L=12, H=768, A=12) |
| 2. BERT-large(L=24, H=1024, A=16) |
L: Transformer 블럭의 숫자, H: Hidden Size, A: Attention block 숫자
L,H,A가 크다는 것은 블럭을 많이 쌓았고, 표현하는 은닉층이 크며, Attention 개수를 많이 사용하였다는 뜻
2.2. MLM & NSP
| 문장의 빈칸채우기 문제 학습 | 두 문장이 주어졌을때 두번째 문장이 첫번째 오는 문장의 바로 다음에 오는 문장인지 여부를 예측하는 방식 |
| 1. 입력의 15%단어를 [MASK] token으로 바꾸어 마스킹 | |
| 1) 80%는 [MASK]로 변경 | 1) 50%는 연속하는 참인문장 |
| 2) 10%는 다른 랜덤 단어로 변경 | 2) 50%는 상관없는 문장 |
| 3) 10%는 바꾸지 않고 그대로 |
3. Transfer Learning(학습된 언어모델 전이학습)
학습한 언어모델을 이용하여 실제 자연어처리 문제를 푸는 과정
4. 결론
BERT는 일반 도메인 데이터로 학습되었기 때문에 일반자연어처리 문제 에서는 잘 동작한다.
특정분야에 사용하려면 특정분야의 학습데이터를 수집하여 언어모델 학습을 추가로 진행해줘야 한다.
-> 이러한 학습데이터를 만들기 위해 수많은 인력과 노력, 시간이 필요


Leave a comment