
문장수준 임베딩(Transformer)
문장수준 임베딩
| 1. 행렬분해 | 잠재의미분석(LSA) |
| 2. 확률모형 | 잠재 디리클레 할당(LDA) |
| 3. 뉴럴네트워크기반 모델 | Doc2Vec |
| ELMo | |
| GPT | |
| BERT |
1. 트랜스포머 네트워크
![]()
1.1. Scaled Dot-Product Attention
입력(X)은 기본적으로 행렬 형태를 가지며 그 크기는 입력 문장의 단어x입력 임베딩의 차원수
드디어, 금요일, 이다 -> 이 레이어의 입력 행렬의 크기는 3x768이 된다. (히든 차원 수가 768차원 이라면)
트랜스포머의 Scaled Dot-Product Attention 매커니즘은 쿼리(query), 키(key), 값(value) 세 가지 사이의 다이내믹스가 핵심
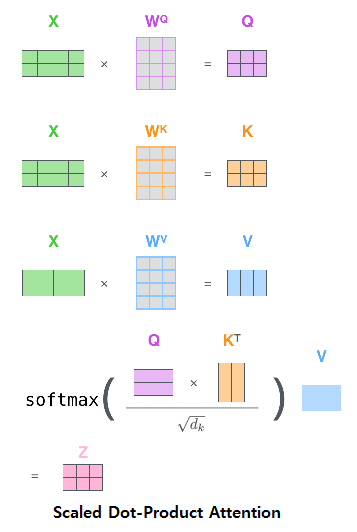
Scaled Dot-Product Attention은 어떻게 단어들 사이의 의미적, 문법적 관계를 포착해 낼 수 있는 걸까.
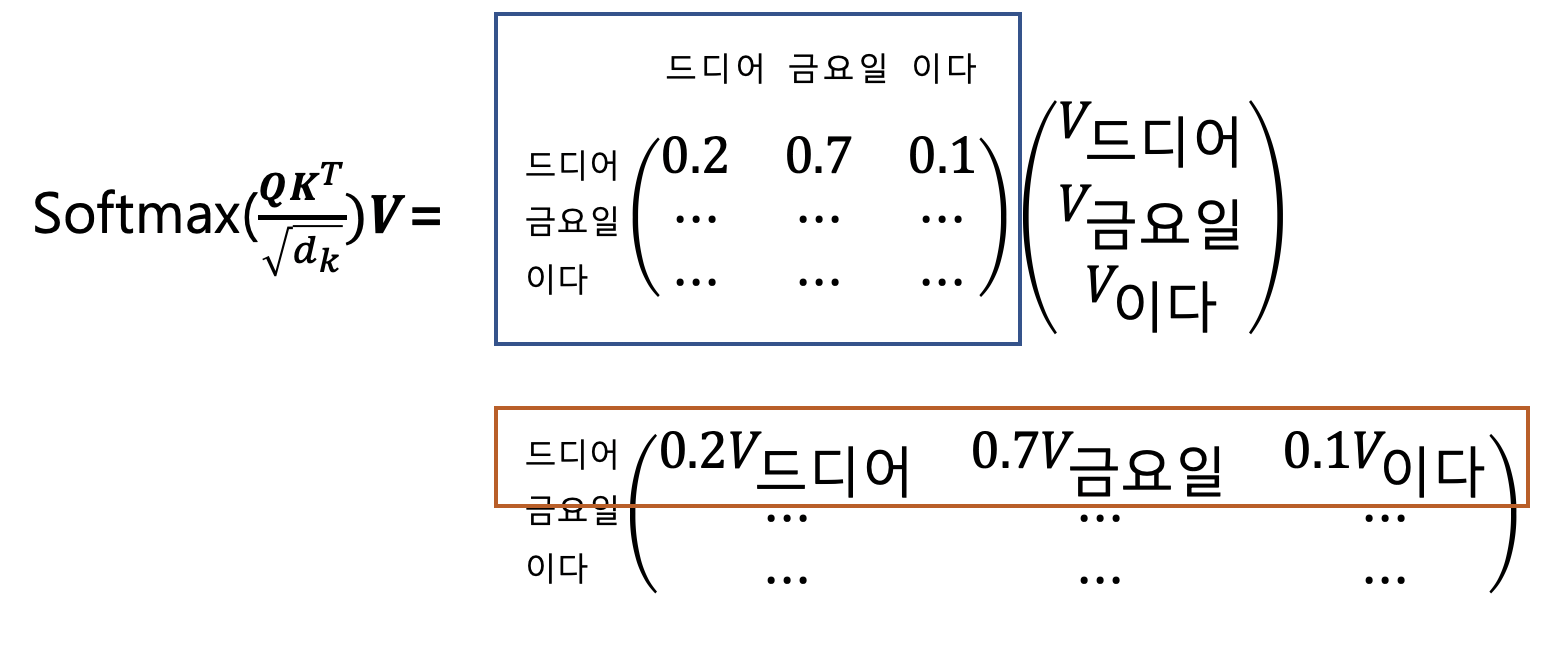
행은 쿼리단어들에 대응하며, 열은 키 단어들에 대응한다. 쿼리 단어들과 키 단어들이 서로 같은걸 확인할 수 있다. 이런 어텐션을 ‘셀프어텐션’ 이라고 한다.
다시말해, 같은 문장내 모든 단어쌍 사이의 의미적, 문법적 관계를 포착해 낸다는 뜻이다.
1.2. 멀티헤드 어텐션
트랜스포머 블록에서 멀티헤드 어텐션은 Scaled Dot-Product Attention을 여러번 시행하는것을 가리킨다.
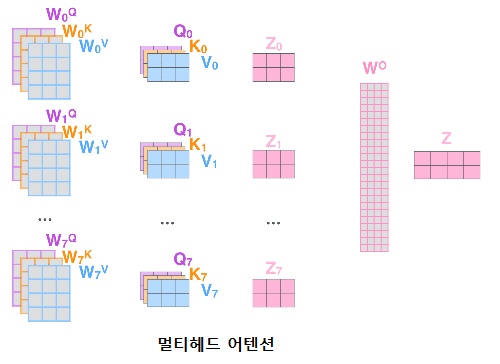
1.3. Position-wise Feedforward Networks
멀티헤드 어텐션 레이어의 출력행렬을 행벡터 단위로


Leave a comment