
단어수준 임베딩(Word2Vec)
Word2Vec
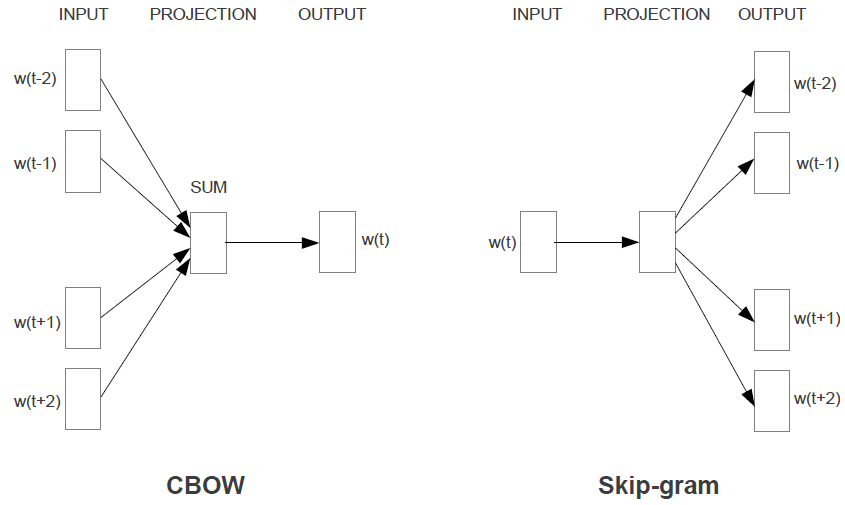
1. 모델기본구조
| 1. CBOW | 주변에 있는 문맥단어(Context Word)들을 가지고 타깃단어(Target Word)하나를 맞추는 과정에서 학습 |
| 2. Skip-gram | 타깃단어를 가지고 주변 문맥단어가 무엇일지 예측하는 과정에서 학습 |
2. 학습 데이터 구축
2.1. Skip-gram 모델의 학습데이터를 구축하는 과정
| … 개울가 에서 속옷 빨래 를 하는 남녀 … |
2.1.1. 포지티브 샘플(Positive Sample): 타깃단어(t)와 그 주변에 실제로 등장한 문맥단어(c)쌍을 가리킨다.
전체 말뭉치를 단어별로 슬라이딩해 가면서 학습 데이터를 만든다. (즉, 같은 말뭉치를 두고도 엄청나게 많은 학습 데이터 쌍을 만들어낼 수 있다.)
| 빨래 | 에서 |
| 빨래 | 속옷 |
| 빨래 | 를 |
| 빨래 | 하는 |
| 를 | 속옷 |
| 를 | 빨래 |
| 를 | 하는 |
| 를 | 남녀 |
2.1.2. 네거티브 샘플(Negative Sample): 타깃단어(t)와 그 주변에 등장하지 않은 단어(말뭉치 전체에서 랜덤 추출)쌍을 의미한다.
(타깃단어가 주어졌을 때 문맥 단어가 무엇일지 맞추는 과정에서 학습될때 계산량이 비교적 큰 단점 보완하기 위해)
타깃단어와 문맥단어쌍이 주어졌을때 해당 쌍이 포지티브 샘플인지, 네거티브 샘플인지 이진분류 하는 과정에서 학습, 이렇게 학습하는 기법을 네거티브 샘플링이라고 한다.
| 빨래 | 책상 | 빨래 | 커피 |
| 빨래 | 안녕 | 빨래 | 떡 |
| 빨래 | 자동차 | 빨래 | 사과 |
| 빨래 | 숫자 | 빨래 | 노트북 |


Leave a comment